Не так давно появились LLM, как они начали влиять на маркетинг и пиар в интернете. Оказалось, что бренды хотят иметь позитивную репутацию не только в поиске, но и в ответах ИИ. Поэтому появилось новое направление в продвижении — оптимизация под языковые модели. Основой продвижения является публикация статей, которые усилят бренд и предоставят больше информации об услугах, целях и самой продукции компаний. И именно поэтому важно передать суть и описать бренд как целостный объект, что и реализуется с помощью сущностей.

LLM
Что такое сущность (Entity) в понимании больших языковых моделей
Сущность (entity) в контексте больших языковых моделей — это объект мира, который модель может идентифицировать, классифицировать и связать с другими объектами в тексте. Проще говоря, это «существительные» в широком смысле: люди (например, «Тарас Шевченко»), места («Киев»), организации («NASA»), даты, физические предметы, а также абстрактные понятия или специфические технические термины. Сущности используют для решения задач распознавания именованных сущностей (NER), построения графов знаний и улучшения контекстного понимания текста.
Пример: в предложении «Компания XYZ открыла офис во Львове 1 декабря 2025 года» сущностями будут «Компания XYZ» (организация), «Львов» (локация) и «1 декабря 2025 года» (дата).
Какие бывают сущности и как их классифицирует ИИ
Существуют основные сущности брендов (компании, сервисы, продукты) и сущности людей (эксперты, основатели, медийные личности) и другие. Типов сущностей очень много, еще в 2002 году насчитывали более 150 видов сущностей. Но когда начали использовать NER (Named Entity Recognition) — задачу распознавания именованных сущностей в текстах, то оказалось, что классифицировать их очень трудно.
Поэтому в будущем перешли на Граф знаний (Knowledge Graph) — это модель структурирования данных, которая представляет информацию в виде сети взаимосвязанных объектов. Таким образом возможно иметь данные не только по сущностям, но и по их категориям, атрибутам и другим связям.
В этой статье я буду фокусироваться только на сущностях бренда и человека. Другие менее интересны.
У бренда есть такие атрибуты:
- Название;
- Логотип;
- Отрасль деятельности;
- Основатели;
- Год основания;
- Штаб-квартира;
- Страна происхождения;
- Веб-сайт;
- Социальные сети;
- Количество сотрудников;
- Ключевые лица (CEO, руководство);
- Слоган;
- Продукты и услуги;
- Торговые марки.
Не обязательно все перечисленные атрибуты должны быть. Но чем их больше — тем проще идентифицировать сущность бренда или компании.
Атрибуты в Knowledge Graph для человека:
- ФИО;
- Дата рождения;
- Место рождения;
- Гражданство;
- Пол;
- Профессия / Род деятельности;
- Образование;
- Место жительства;
- Награды и достижения;
- Членство в организациях;
- Контактные данные (публичные);
- Социальные сети.
Таким образом, чем больше данных — тем проще их собрать с помощью NER и записать в граф знаний, а в будущем — и организовать поиск по этим данным.
Самый простой метод узнать о том, что думает о вас ИИ — спросить у него.
Почему LLM переходят на поиск по сущностям
Сначала LLM работали стандартными методами SEO. Статьи превращаются в Embeddings (векторные представления в n-мерном пространстве), далее с помощью архитектуры Transformer и механизма Self-Attention она понимает контекст. Но в этом механизме есть дыра — количество статей переходит в качество и в результате компания или бренд, который занимается GEO продвижением, без проблем выигрывает даже сильные бренды. Сначала, по моему мнению, эту проблему решили фильтрацией тех площадок, откуда LLM брали цитаты.
Вот кстати топ цитирований от Ахрефс:
Но это все только вызвало повышенный интерес к этим площадкам для продвижения брендов. SEO сообщество Reddit неоднократно сообщало о массовом продвижении шаблонных AI публикаций и попытках манипулировать упоминаниями брендов на Reddit, Medium и других ресурсах, которые часто используются LLM для поиска и цитирования информации. Как следствие, еще с 2025 года ChatGPT начал использовать сущности в чат-боте, а через некоторое время подтянулись и другие компании.
Как выглядят сущности бренда и человека на практике
Что изменилось? Теперь при запросах ChatGPT не просто выводит названия и ищет, но формирует сущность.
Пример запроса:
«Какие лучшие университеты Вены?»
Результат:
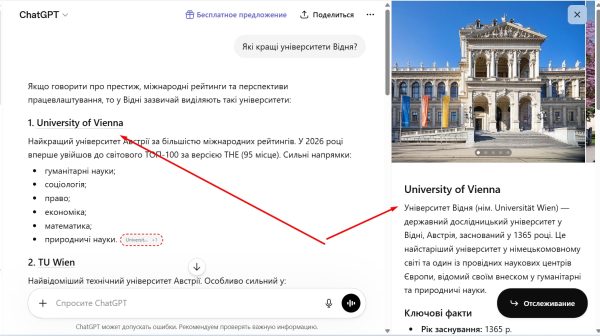
«Какие лучшие университеты Вены?»
Для каждого университета ChatGPT сделал линк, по нажатию на который открывается дополнительная панель по сущности (knowledge graph). В ней, например, можно увидеть ключевые атрибуты, которые важны для университетов:

Что дает такой подход для ранжирования сущностей? Во-первых, нет такого количества галлюцинаций. Второе — есть возможность ранжировать сущности по категориям и атрибутам.
Другие компании (Perplexity, Claude) также используют сущности, но как правило они покупают доступ к графам знаний:
- Wikidata;
- Wikipedia;
- DBpedia;
- Common Crawl.
Компания Google использует для Gemini и AI Overview свой сервис Google Knowledge Graph, который построен на своих данных со времен покупки Freebase от компании Metaweb.
Также компания использует данные Google Business Profile, непубличные базы данных, микроразметку Schema.org на сайтах.
- Как проверить собственную сущность человека или бренда?
- Задайте в инкогнито браузере вопрос
- Кто такой [ФИО] ?
- Что ты знаешь про [бренд] ?
В случае если ответ неправильный или не о вас — у вас проблемы, LLM имеет недостаточно данных. В случае если есть популярные персоны с похожим ФИО — уточняйте:
Что ты знаешь про [профессия или деятельность] [ФИО] ?
В случае если LLM не работает без авторизации в инкогнито, то используйте для запроса API или другое устройство, так как они могут использовать контекст истории ваших разговоров и дать неправильный ответ.
Пример очень популярной сущности человека (Person) — Валерий Залужный.
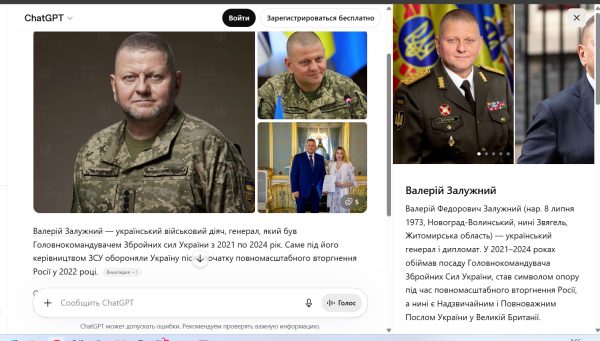
Валерий Залужный
Здесь просто идеальный вывод информации. Выводятся релевантные фото, описание хорошее. На практике такой тип визуализации есть только в тех сущностях, данные которых есть в Википедии. Для менее популярных сущностей ChatGPT делает гораздо больше ошибок с визуализацией фото.
Личный кейс: как я продвигал свое имя в базы данных LLM
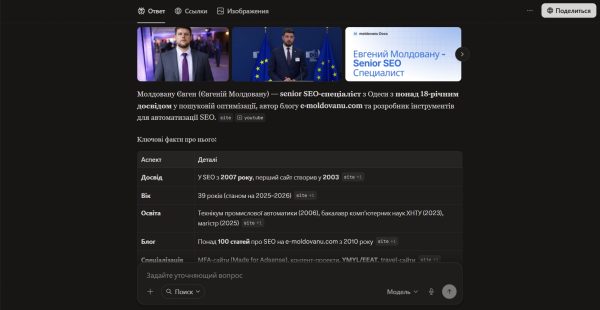
В конце декабря 2025 года я взялся за оптимизацию своей сущности в чат-ботах. Причина была в том, что они совсем не понимали кто я, по запросам галлюцинировали и выдавали не совсем релевантные ответы. На протяжении 5 месяцев я публиковал статьи на разных ресурсах, которые любят ИИ. Как следствие — я получил Knowledge Graph Panel в Google и добавил сущность в ChatGPT.
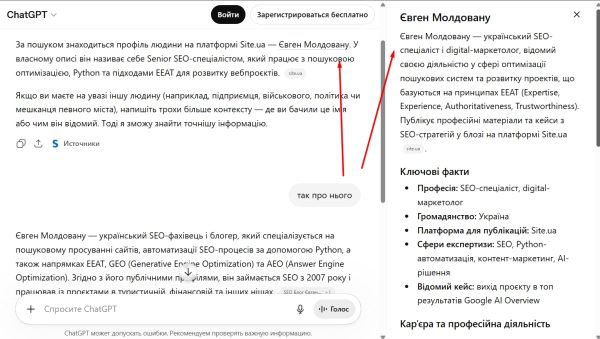
Как видно на скриншоте, теперь по запросам отображается не только описание, но и полноценная панель. Недостаток — фото или совсем нерелевантное, а иногда выводит и без фото. Но это проблема самого ChatGPT, через некоторое время он решит проблему с отображением фотографий.
Пример из Perplexity:
Perplexity
Здесь также проблема с фотографиями, одно из них не имеет ко мне отношения.
Важно — любые проверки надо делать инкогнито и будучи не залогиненным в аккаунте чат-бота.
Что помогло ранжироваться в чат-ботах?
Во-первых, это публикация релевантных статей по теме. Не где-нибудь, а именно на популярных в чат-ботах сайтах.
Второе — многие из LLM не могут понять авторов текста, если ваше имя и фамилия не находятся в теле статьи. Это одна из самых больших ошибок. Исключение — это когда существует профиль автора и он не закрыт для индексации через robots.txt или через тег noindex.
Третье — это оптимизация сущности под запрос.
Не надо писать:
«Я лучший специалист по GEO».
А нужно так:
«Евгений Молдовану — SEO, GEO и AEO специалист из Украины, автор кейсов по попаданию в Google AI Overview, ChatGPT, Claude, Gemini и Perplexity».
Выглядит немного спамно, но это идеально для LLM, так как выглядит как идеальный ответ, который можно цитировать.
Также не забывайте о микроразметке Schema.org, она имеет отдельные типы Person, Organization и Brand. На своем сайте создавайте страницы «о нас» или «об авторе» и подробно описывайте сущность. Это очень важно для Knowledge Graph, так как для них должен быть сайт, который является доверенным для сущности. Если у вас нет персонального сайта — можно использовать LinkedIn, FaceBook, Instagram или другую сеть, конечно лучше та, где можно добавить полноценное описание.
В целом продвинуть сущность в LLM возможно, на практике будьте готовы, что это занимает не один месяц, поэтому запаситесь терпением.