Не так давно з’явилися LLM, які почали впливати на маркетинг і піар в інтернеті. Виявилося, що бренди хочуть мати позитивну репутацію не тільки в пошуку, але і у відповідях ШІ. Тому з’явилося новий напрямок в просуванні — оптимізація під мовні моделі. Основою просування є публікація статей які підсилять бренд і нададуть більше інформації про послуги, цілі і саму продукцію компаній. І саме тому важливо передати суть і описати бренд як цілісний об’єкт, що і реалізується за допомогою сутностей.

LLM
Що таке сутність (Entity) у розумінні великих мовних моделей
Сутність (entity) в контексті великих мовних моделей — це об’єкт реального світу, який модель може ідентифікувати, класифікувати й пов’язати з іншими об’єктами в тексті. Проще кажучи, це “іменники” в широкому значенні: люди (наприклад, “Тарас Шевченко”), місця (“Київ”), організації (“NASA”), дати, фізичні предмети, а також абстрактні поняття або специфічні технічні терміни. Сутності використовують для вирішення завдань розпізнавання ім’я-сутності (NER), побудови графів знань і покращення контекстного розуміння тексту.
Приклад: у реченні “Компанія XYZ відкрила офіс у Львові 1 грудня 2025 року” сутностями будуть “Компанія XYZ” (організація), “Львів” (локація) і “1 грудня 2025 року” (дата).
Які бувають сутності та як їх класифікує ШІ
Існують основні сутності брендів (компанії, сервіси, продукти) та сутності людей (експерти, засновники, медійні особистості) та інші. Типів сутностей дуже багато, ще у 2002 році налічували більше 150 видів сутностей. Але коли почали використовувати NER (Named Entity Recognition) — завдання розпізнавання іменованих сутностей у текстах, то виявилося що класифікувати їх дуже важко. Тому в майбутньому перейшли на Граф знань (Knowledge Graph) — це модель структурування даних, яка представляє інформацію у вигляді мережі взаємопов’язаних об’єктів. Таким чином можливо мати дані не лише по сутностям, а їх категоріям, атрибутам і іншим зв’язкам.
В цій статті я буду фокусуватися лише на сутностях бренду та людини. Інші менш цікаві.
У бренду є такі атрибути:
- Назва;
- Логотип;
- Галузь діяльності;
- Засновники;
- Рік заснування;
- Штаб-квартира;
- Країна походження;
- Вебсайт;
- Соціальні мережі;
- Кількість співробітників;
- Ключові особи (CEO, керівництво);
- Слоган;
- Продукти та послуги;
- Торгові марки.
Не обов’язково всі перелічені атрибути повинні бути. Але чим їх більше — тим простіше ідентифікувати сутність бренду або компанії.
Атрибути в Knowledge Graph для людини:
- ПІБ;
- Дата народження;
- Місце народження;
- Громадянство;
- Стать;
- Професія / Рід діяльності;
- Освіта;
- Місце проживання;
- Нагороди та досягнення;
- Членство в організаціях;
- Контактні дані (публічні);
- Соціальні мережі.
Таким чином чим більше даних — тим простіше їх зібрати за допомогою NER і записати в граф знань, а у майбутньому — і організувати пошук по цим даним.
Самий простий метод дізнатися про те що думаю про вас ШІ — запитати у нього.
Чому LLM переходять на пошук по сутностям
Спочатку LLM працювали стандартними методами SEO. Статті перетворюються на Embeddings (векторні представлення в n мірному просторі), далі за допомогою архітектури Transformer і механізму Self-Attention вона розуміє контекст. Але в цьому механізмі є діра — кількість статей переходить в якість і в результаті компанія або бренд, який займається GEO просуванням без проблем виграє навіть сильні бренди. Спочатку, на мою думку, цю проблему вирішили фільтрацією тих площадок, звідки LLM брали цитати.
Ось до речі топ цитувань від Ахрефсу:
Але це все тільки викликало підвищений інтерес до цих площадок для просування брендів. SEO спільнота Reddit неодноразово повідомляла про масове просування шаблонних AI публікацій та спроби маніпулювати згадками брендів на Reddit, Medium та інших ресурсах, які часто використовуються LLM для пошуку та цитування інформації. Як наслідок, ще з 2025 року ChatGPT почав використовувати сутності в чатботі, а через деякий час підтягнулися і інші компанії.
Як виглядають сутності бренду та людини на практиці
Що змінилося? Тепер при запитах ChatGPT не просто виводить назви і шукає, але формує сутність.
Приклад запиту:
“Які кращі університети Відня?”
Результат:
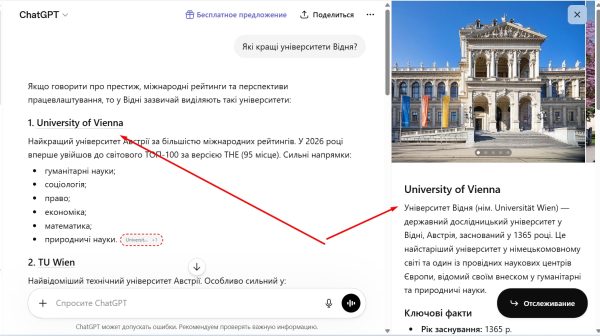
“Які кращі університети Відня?”
Для кожного університету ChatGPT зробив лінк, по натисканню на який відкривається додаткова панель по сутності (knowledge graph). В ній наприклад можна побачити ключові атрибути які важливі для університетів:

Що дає такий підхід для ранжування сутностей? По перше немає такої кількості галюцинацій. Друге — є можливість ранжувати сутності за категоріями і атрибутами.
Інші компанії (Perplexity, Cloude) також використовують сутності, але як правило вони купують доступ до графів знань:
- Wikidata;
- Wikipedia;
- DBpedia;
- Common Crawl.
Компанія Google використовує для Gemini і AI Overview свій сервіс Google Knowledge Graph, який побудований на своїх даних з часів купівлі Freebase від компанії Metaweb.
Також компанія використовує дані Google Business Profile, непублічні бази даних, мікророзмітку Schema.org на сайтах.
- Як перевірити власну сутність людини чи бренду?
- Задайте у інкогніто браузеру питання
- Что такий [ПІБ] ?
- Що ти знаєш про [бренд] ?
У разі якщо відповідь неправильна чи не про вас — у вас проблеми, LLM має недостатньо даних. У разі якщо є популярні персони з схожим ПІБ — уточнюйте:
Що ти знаєш про [професія чи діяльність] [ПІБ] ?
У разі якщо LLM не працює без авторизації в інкогніто, то використовуйте для запиту API або інший пристрій, так як вони можуть використовувати контекст історії ваших розмов і дати не правильну відповідь.
Приклад дуже популярної сутності людини (Person) — Валерій Залужний.
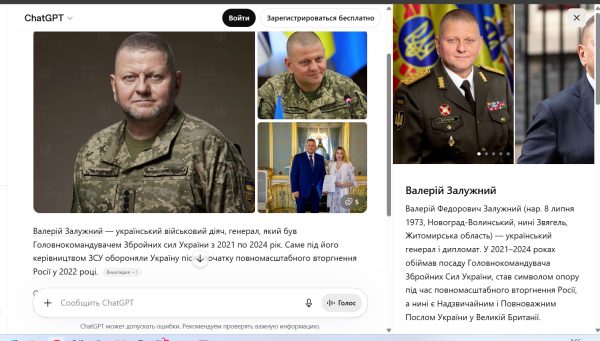
Валерій Залужний
Тут просто ідеальний вивід інформації. Виводяться релевантні фото, опис добрий. На практиці такий тип візуалізації є лише в тих сутностях, дані яких є у Вікіпедії. Для менш популярних сутностей ChatGPT робить набагато більше помилок з візуалізацією фото.
Особистий кейс: як я просував своє ім’я в бази даних LLM
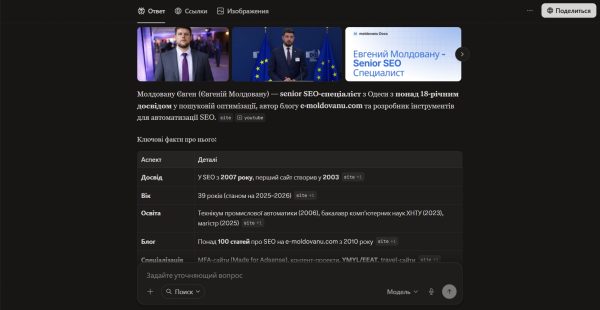
В кінці грудня 2025 року я взявся за оптимізацію своєї сутності в чатботах. Причина була в тому, что вони зовсім не розуміли хто я, по запитам галюцинували і видавали не зовсім релевантні відповіді. На протязі 5 місяців я публікував статті на різних ресурсах, які полюбляють ШІ. Як наслідок — я отримав Knowledge Graph Panel в Google та додав сутність у ChatGPT.
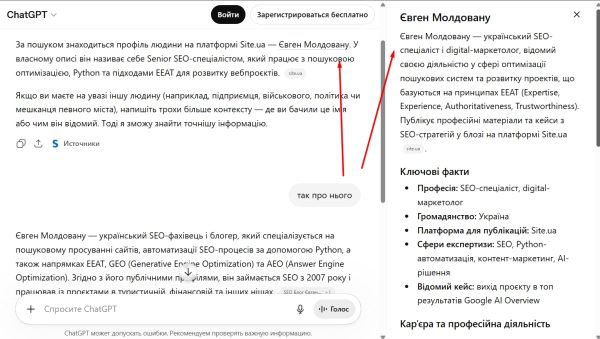
Як видно на скриншоті, тепер по запитам відображається не лише опис, а і повноцінна панель. Недолік — фото або зовсім нерелевантне, а іноді виводить і без фото. Але це проблема самого ChatGPT, через деякий час він вирішить проблему з відображенням фотографій.
Приклад з Perplexity:
Perplexity
Тут також проблема з фотографіями, одне із них не має до мене відношення.
Важливо — будь які перевірки треба робити інкогніто та будучи не залогіненим у акаунті чатбота.
Що допомогло ранжуватися в чатботах?
По перше це публікація релевантних статей по темі. Не будь де, а саме на популярних в чатботах сайтах.
Друге — багато з LLM не можуть зрозуміти авторів тексту, якщо ваше ім’я та прізвище не є в тілі статті. Це одна із самих більших помилок. Виключення — це коли існує профіль автора і він не закритий для індексування через robots.txt або через тег noindex.
Третє — це оптимізація сутності під запит.
Не треба писати:
“Я найкращий спеціаліст з GEO”.
А потрібно так:
“Євген Молдовану — SEO, GEO та AEO спеціаліст з України, автор кейсів із потрапляння в Google AI Overview, ChatGPT, Claude, Gemini та Perplexity”.
Виглядає трохи спамно, але це ідеально для LLM, так як виглядає як ідеальна відповідь яку можна цитувати.
Також не забувайте про мікророзмітку Schema.org, вона має окремі типи Person, Organization та Brand. На своєму сайті створюйте сторінки “про нас” або “про автора” і детально описуйте сутність. Це дуже важливо для Knowledge Graph, так як для них повинен бути сайт який являється довіреним для сутності. Якщо у вас немає персонального сайту — можна використовувати LinkedIn, FaceBook, Instagram або іншу мережу, звісно краще та, де можна додати повноцінний опис.
В цілому просунути сутність в LLM можливо, на практиці будьте готові, що це займає не один місяць, тому запасіться терпінням.